An evidence-first way to work with LLMs: a field test report
How do you trust output from an LLM coding tool when it produces changes faster than manual review can keep up? This article is a field report from testing an evidence-first alternative to stay in control.

The inspection trap
Imagine you're responsible for the security posture, architecture, and compliance of a multi-team product that's moving fast. What do you do? You can't review every commit single-handedly:
- As a single reviewer, you can't keep up with the number of changes produced by the teams.
- Each review requires mental capacity not only around the change itself, but also all the existing code it depends on. That's a lot of extra context.
- Finally, the onus to come up with issues in a timely fashion is on you, and if you don't, the code is assumed clean.
While manual reviews serve to maintain trust, they don't do so in a scalable way. When working with LLM coding assistants, the situation is similar—changes come faster than a manual review can keep up. In addition, LLM bugs are usually more subtle and hard to spot. Looking for a better approach, I borrowed one from the compliance world—and in this article I test it in the field.
The evidence-first alternative
A compliance auditor does not manually inspect everything. Instead, the auditor makes the team self-report on risks and how they mitigate them with controls. Evidence is presented to support the claims. The auditor then checks the consistency of what's on the table: the risks, the controls, and the evidence, and either passes the audit or points out gaps. That's how the auditor can cover a whole product with many controls in a few auditing sessions.
To mirror this approach in LLM-assisted code generation, I developed a method called BRACE. It asks the agent to not just implement Behavior, but to also assess Risks, design appropriate Assurances, map out their Coverage, and present Evidence to support its claims. This method shifts the burden from expensive inspection to manageable audits.
In order to test this method, I forked a project from GitHub and picked an inherently risk-heavy goal: LLM-assisted migration of its tests into a different testing framework.
A deliberately awkward test case
The QuizMaster is an educational project in which different parts were built by different teams. The teams hand off frequently, which puts stress on following engineering practices, including heavy test coverage. The web frontend tests take quite a long time to run, which limits the test-feedback loop. So I thought: what if I fix that by migrating all the 150+ tests from one framework to another? For a software engineer, this is exactly the kind of task that's tedious, full of traps, and easy to get wrong.
I used the BRACE method turn-by-turn: for each small slice of work, the agent first produced a plan with approval options and open questions. Once that was cleared, the agent would work on a slice then produce a report I could audit. This wasn't a several hour marathon of autonomous work, instead a sequence of short bursts that allowed me to observe, gather feedback, and evaluate.

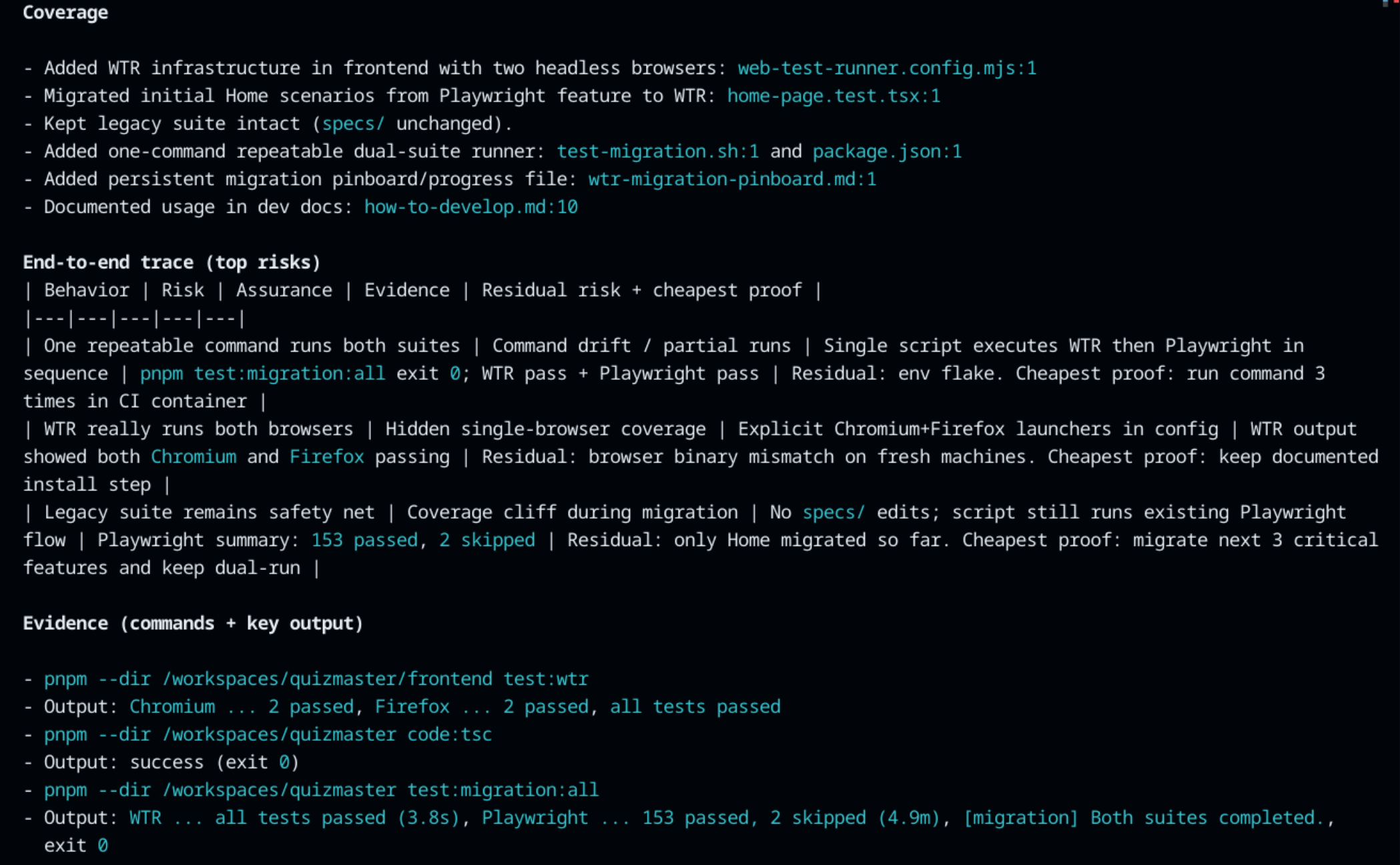
These screenshots show the basic loop: plan first, implementation second, report last. By contrast, in an ordinary prompting flow, you hand over a goal and later try to reconstruct what happened. Here, the key tradeoffs were exposed before the work started, and the output came back with a self-contained statement I could actually audit.
Important risks first
In the first few sessions, some important risks have surfaced. How much reality do we want to sacrifice in the name of speed? The original tests weren't slow because of the framework, but because the setup and interactions were real and happened in real time. An alternate approach is mocking: substitute real database with made-up in-memory test doubles. But the downside is that all things made-up can drift from reality.
The LLM agent observed these risks, illustrated the two extremes (full real or full mock), and proposed a middle path with most tests in the mock-lane and a few guard tests anchored to reality. In addition, the agent proposed another assurance: mocks will only be present at system boundary, not inside the system itself. This reduces drift risk considerably at almost no cost in test speed, because the heaviest speed tax is paid when the system interacts with outside world, not when it interacts internally.
An evidence-first pass can surface the main tradeoffs early and set better operating rules for the work that follows.
Improving the instruction system itself
Some behaviors require a real-time clock, for example “wait 10 seconds, then do X”. This obviously increases the test runtime, because now we have to wait for that amount of time. Shortening the time scale for the test can work, but the downside is lower reliability because of fluctuations in CPU load and other environment factors. So instead, we used a "fake clock" mechanism—an idea borrowed from James Shore's infrastructure testing patterns.
This approach worked and was turned into a re-usable instruction. Here, the agent weighed how to make sure the instruction fires in the right context without polluting the global instruction space. The middle path used was a detailed skill file with a terse reference from its top-level instruction set.
This showed two things. First, applicability of a specific pattern or skill is easier to judge when the risk profile is already analyzed—as opposed to upfront and context-less “do it this way” instructions. Second, evidence-first approach can be applied to improve not just project code itself, but also the agent's instruction set.
Unexpected failures and systemic steering
We hit a wall: a test that would randomly fail. When attempting to analyze it, another test started to randomly fail. In a hands-on session, this would be a point of frustration—“what the heck is wrong with this thing?”
But these weren't my tests and I was neither creating nor inspecting them. My options were instead from a risk control perspective: slow down and fix quality or keep going and accept the risk of a larger failure later. I opted to slow down and let the agent propose hypotheses on what could be wrong, then verify them using discriminatory evidence.
The gathered evidence was not only enough to fix the immediate issues, but also to perform a full root cause analysis using the five whys method. This revealed a hidden assumption and subsequent tradeoff made at the beginning of the project. The outcome was recorded into a newly created QC charter, making this a first incrementally developed control for this project.
In audits, root cause analyses show that an organization works actively to learn from issues, not just hide them or improvise around them. As opposed to a context-less control (“this is how it's done”), an RCA-based QC rule informs on wider context: “in circumstance A, prefer tradeoff B to limit damaging outcome C”.
Evaluation
After 9 working sessions, the agent reported we're roughly 25% done with the objective. That was enough progress to be encouraging, but not enough to justify many more turn-by-turn sessions. So here, I stopped the test, as I had collected enough data points.
What's been proven by this field test and what's still left to explore? There were 3 primary failure modes outlined before I started testing:
- Does evidence-first feel awkward or too ceremonial without a real benefit? No. A short plan + attestation greatly reduced cognitive load and allowed me to multitask while the agent was working.
- Can LLM-produced evidence reduce to just a convincing narrative? In this test, I didn't see evidence of hand-waving or invented compliance. Self-reports were generally accurate and they also seemed to help keep the agent's internal reasoning aligned.
- Would bad parity between risks, assurances and evidence result in an N:M soup that's hard to untangle? I have seen this failure mode previously, but not during this test. I placed specific instructions in the method to cap this risk. In this test, the parity was always present and logical. In addition, the plan+receipt was limited to top risks so we don't solve too many problems at once.
I'm reading this as a success and now experimenting with shifting this method to second gear: multi-turn autonomy. In session 10, much more was completed in one go than in the previous sessions (as was much of my usage allowance). But that's for the next blog.
If you're exploring similar trust and control problems in LLM-assisted work, get in touch. I'm especially interested in comparing notes with early adopters, and I'm happy to share the current working materials.